ローカルでRAGを動かしてみよう 02: RAG ナレッジデータの準備

挨拶
こんにちは、リリです。今回は LLM が参照する資料であるナレッジデータを準備する過程について紹介していきます。
ナレッジデータとは?
ナレッジデータとは、LLM が回答生成の参考にする外部情報です。PDF、TXT、CSV、HTMLなどのドキュメント形式や、構造化されたデータベースなども含まれます。質問に対して適切な回答を生成するため、これらの情報を検索・抽出し、生成AIと組み合わせて使います。
ナレッジデータ準備の過程
ナレッジデータ準備過程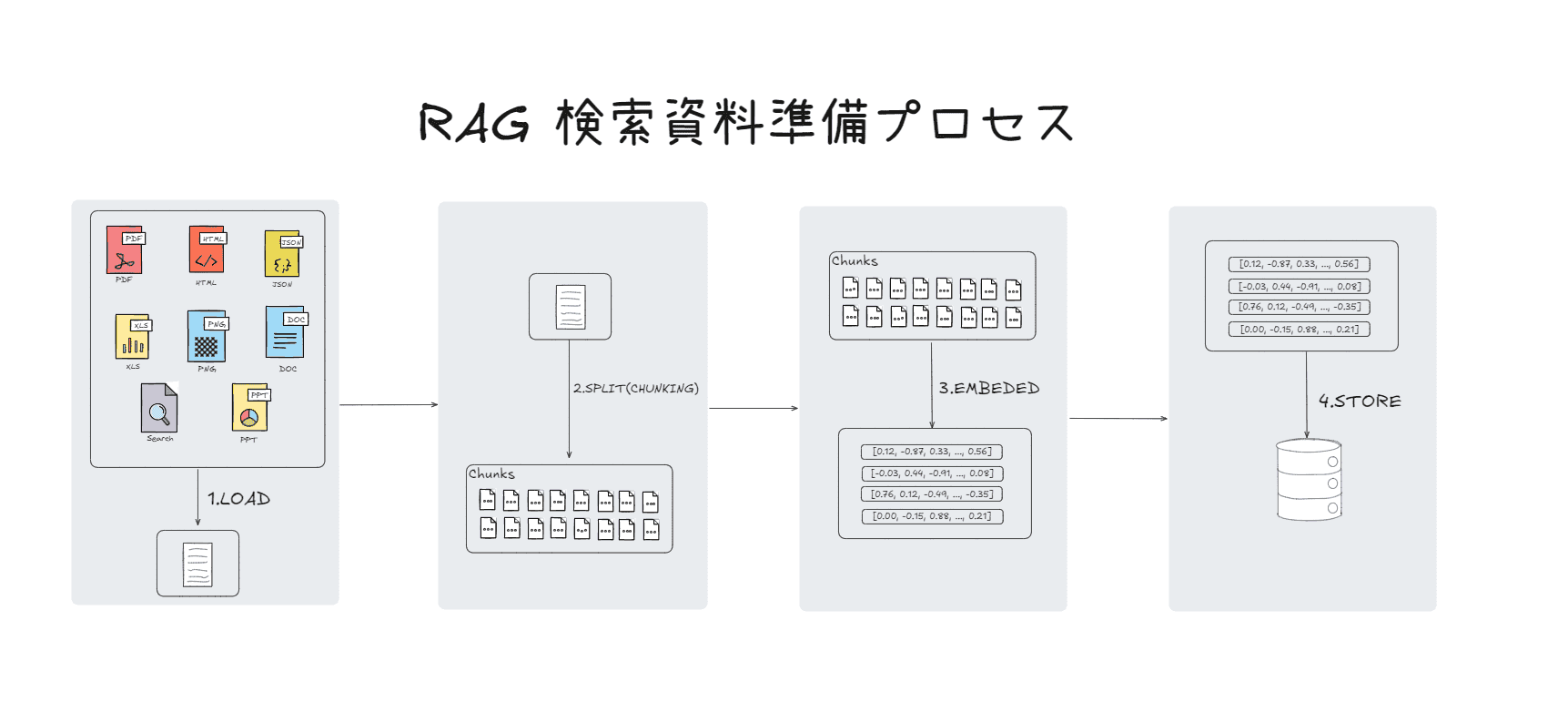
ナレッジデータの準備は、大きく4つのステップに分かれます。(Load → Split → Embed → Store)
1.ファイルの読み込み(Load)
PDFをテキストに変換
最初は、準備したファイルをプログラムに取り込む「読み込み」の段階です。 txt や csv などの形式はシンプルですが、実務で扱う文書の多くは PDF 形式です。
PDF は、レイアウトや埋め込みフォント、スキャン画像の有無などにより、テキストの抽出精度に差が出やすい形式です。
そのため、読み込み処理では最も注意が必要なファイルタイプといえます。
このあたりの詳細な違いや対処方法については、別の記事で紹介する予定です。
2. テキストの分離(SPLIT)
チャンク処理の流れ
読み込んだテキストは「チャンク」と呼ばれる単位に分割されます。
チャンクごとに意味が保たれるように、段落や文単位で分けるのが一般的です。
このようにテキストを分割するのは LLM が入力として処理できるトークン数に上限があるためです。この上限を超えた部分はモデルで処理されず、無視されるか、エラーになることがあります。 また、テキストが長すぎる場合重要でない情報を含む可能性があります。それが RAG の精度低下につながる原因となることもあります。
チャンクの役割
チャンクを作成する際は、各チャンクがそれ単体でも意味を持っているように分割することが重要です。 そのため、文や句、段落など、文書の構造に基づいて分割する方法がよく用いられます。
チャンクのサイズ
各チャンクのサイズは、その利用目的に応じて調整可能です。大規模言語モデル(LLM)への入力制限や運用コストを鑑みながら、アプリケーションに最適なサイズを設定する必要がある。たとえば、単語数または文字数を基準としてチャンクを分割する等の方法が考えられる。
下記は、テキストを一度 chunk として分割する例です。
チャンクのオーバーラップ(overlap)
チャンクを分割する際、各チャンクの末尾と次のチャンクの先頭が一部重なるようにする手法をオーバーラップ(overlap)と呼びます。 オーバーラップは情報の切れ目によって意味が途切れることを防ぎ、文脈の連続性を保つために有効です。
チャンクのオーバーラップ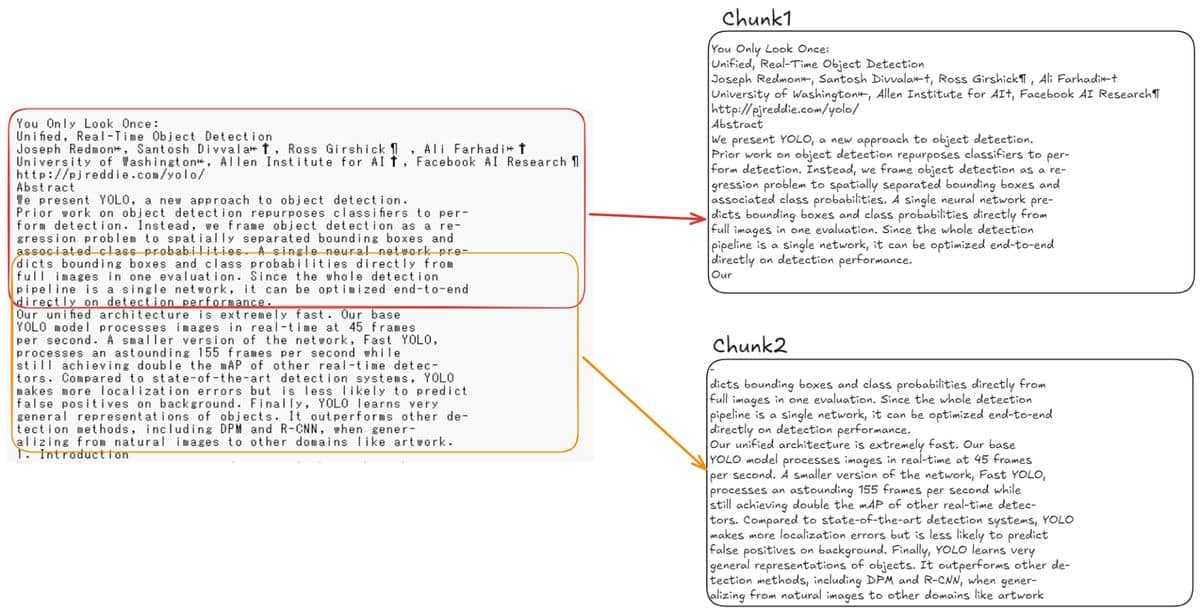
たとえば上記の例文では、Chunk1の末尾が「Our」で終わっており、文が途中で区切られていることが確認できます。そのためChunk2では、同じ文の文頭「dicts bounding boxes…」から始まっており、チャンク間で文単位の重複が行われていることがわかります。
したがって、オーバーラップを用いたチャンク分割は、長文を処理する際に意味の断絶を避け、モデルがより正確に文脈を理解・保持できるようにするため重要な手法といえます。
3. 埋め込み
テキストのベクトル化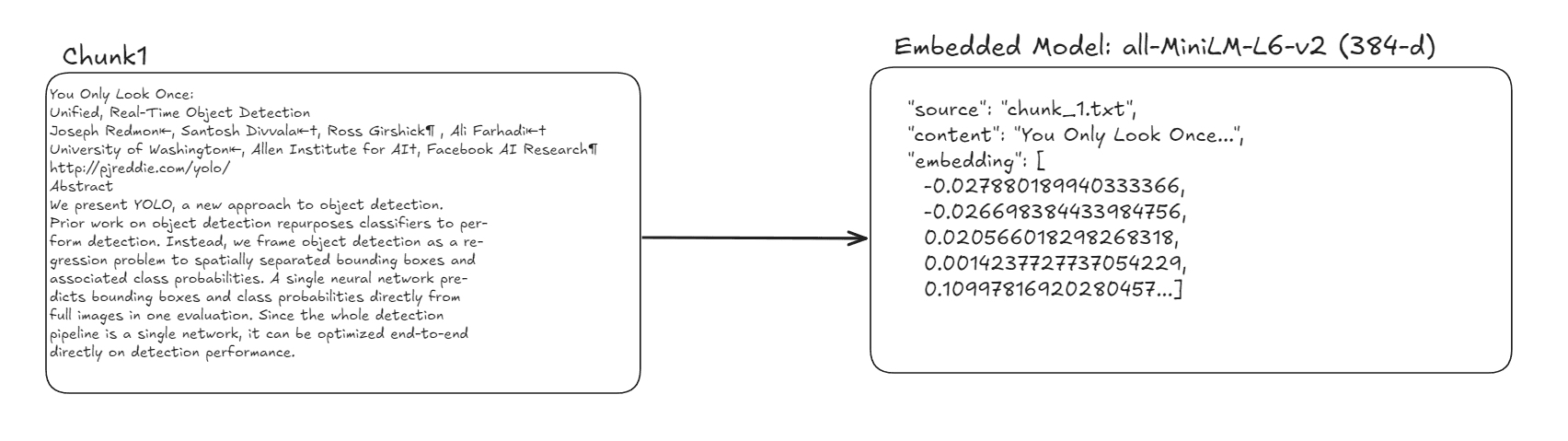
分割されたチャンクは、その意味的情報が保持されたまま、ベクトル(数値配列)へと変換されます。このプロセスを「埋め込み( Embedding )」と称します。
このベクトルは、後続の検索処理において活用され、生成AIが回答を生成する際に参照される情報源として提供されます。
利用する埋め込みモデルは、その用途および要求される精度に応じて適切に選定される必要があります。
ベクトル化とは?
LLM は、人間のように文字そのものを理解しているわけではありません。 その代わりに、文章や単語を「ベクトル」と呼ばれる数値の塊に変換して処理しています。
単語を数値で表す
たとえば、ラーメンの味を任意の値として並べたと仮定して、以下のように1つの数値で表すことができます。 この値は、ベクトル化のイメージをつかむための簡略化された例です。
- 塩味:0.1
- 醤油味:0.5
- 味噌味:0.8
ここで「辛味噌味」を加えると、味噌味に近いので 0.85 あたりの数値になると考えられます。
このように、数値が近いほど意味も似ていると判断されます。
検索例
次は検索の例を見てみます。
質問:
「塩ラーメンについて教えて」 → 0.2
文の候補(チャンク):
- Chunk1:塩ラーメンとは、ダシを塩タレで調味したスープに、茹でた中華麺を入れたラーメンです。 →
0.12 - Chunk2:醤油ラーメンは、スープに醤油ベースのタレを使用したラーメンのことです。 →
0.53
この場合、0.2 に近い 0.12 の Chunk1 が「意味が近い」として選ばれます。
※ ただし実際の検索では、このような単純な数値ではなく、より高次元のベクトルを使って類似度を計算します。
実際のベクトルは1つの数字ではない
ここまで簡単のために「1つの数」で例を出しましたが、実際の AI はもっと複雑です。 たとえば OpenAI の embedding model は1536の配列(1536次元ベクトル)を扱っています。
埋め込みモデルの選定
多言語への対応性や専門用語に対する適応性を考慮したうえでモデルを選定することが重要です。たとえば、日本語文書を取り扱う場合には、日本語に特化したモデルを使用しないと精度低下の可能性があります。
更新時の再埋め込み
ナレッジデータが更新された場合、該当部分に対する再埋め込みが必須となります。変更差分のみを処理する設計とすることで、効率的な運用が実現可能です。
4. 格納
埋め込み処理が完了したベクトルは、「ベクトルデータベース( Vector DB )」へと格納されます。 このデータベースでは、ユーザーからの質問に対して最も関連性の高いチャンクを検索(類似検索)し、その検索結果が回答生成に活用されます。 代表的なベクトルDBとしては、Chroma、Weaviate、FAISS などが挙げられます。
検索品質への直接的影響
ベクトルDBのパラメーターには、ベクトルの近さを測る「距離関数」や、似ていると判断する基準である「スコア閾値」などがあり、検索精度に大きな影響を与えます。
スケーラビリティの考慮
データ量の増加に伴い、検索速度やストレージ要件が変動するため、初期段階から拡張性を見据えた設計が望ましいと言えます。
メタデータの付加
各チャンクに「文書名」や「ページ番号」などのメタデータを付加しておくことで、検索結果のフィルタリングやユーザーインターフェース(UI)表示において有用となります。
終わりに
今回は、RAG を構築するうえで土台となるナレッジデータの準備について、4つのステップ(Load → Split → Embed → Store)に分けて整理しました。 特にチャンク化やベクトル化のイメージをつかむことで、RAG の内部動作に対する理解が深まったと思います。
次回は、この処理を実際にコードに落とし込みながら、Ollama と LangChain を組み合わせてローカル環境(WSL)上で動かす方法を紹介します。
RAG のしくみを実装レベルで理解したい方は、ぜひ次回もご覧ください。

